| Model |
Back εcos(↓) |
Front εcos(↓) |
Left εcos(↓) |
Right εcos(↓) |
Aggregated |
Preferred |
| Same |
Rev. |
Same |
Rev. |
Same |
Rev. |
Same |
Rev. |
Tran. |
Rot. |
Ref. |
| InstructBLIP-7B |
45.6 |
39.0 |
31.6 |
52.0 |
37.2 |
48.0 |
47.5 |
37.8 |
40.5 |
44.2 |
43.9 |
- |
| InstructBLIP-13B |
40.9 |
45.5 |
46.0 |
37.4 |
43.4 |
44.9 |
45.6 |
41.6 |
44.0 |
42.3 |
43.0 |
- |
| mBLIP |
51.2 |
53.7 |
51.2 |
47.9 |
52.4 |
53.5 |
54.6 |
46.8 |
52.3 |
50.5 |
52.1 |
- |
| GLaMM |
58.3 |
33.3 |
43.9 |
42.9 |
38.3 |
51.8 |
17.3 |
63.7 |
39.5 |
47.9 |
33.0 |
Ref. |
| LLaVA-1.5-7B |
54.0 |
32.9 |
59.1 |
24.8 |
11.9 |
70.0 |
13.0 |
68.5 |
34.5 |
49.0 |
20.7 |
Ref. |
| LLaVA-1.5-13B |
61.8 |
19.2 |
56.0 |
27.7 |
31.7 |
61.8 |
24.3 |
64.3 |
43.4 |
43.2 |
25.7 |
Ref. |
| XComposer2 |
73.2 |
17.9 |
74.5 |
20.7 |
20.1 |
80.9 |
21.3 |
81.1 |
47.3 |
50.1 |
20.0 |
Ref. |
| MiniCPM-V |
70.9 |
21.9 |
64.3 |
26.9 |
19.7 |
74.1 |
21.1 |
73.3 |
44.0 |
49.1 |
22.4 |
Ref. |
| GPT-4o |
75.7 |
28.2 |
73.6 |
32.0 |
24.3 |
80.8 |
25.1 |
80.8 |
49.7 |
55.5 |
27.4 |
Ref. |
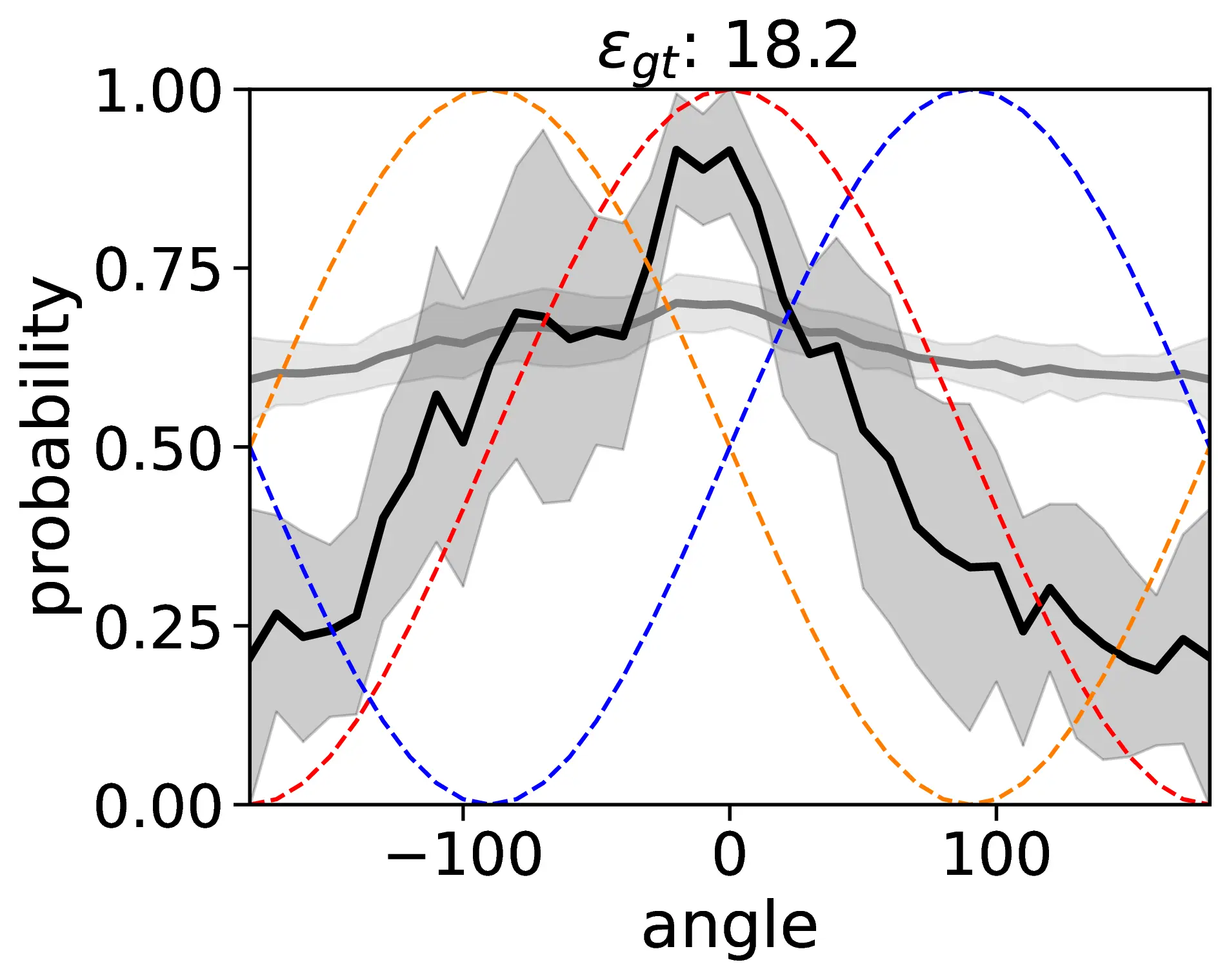
Preferred coordinate transformation mapping from the egocentric viewer (camera) to the relatum in the relative FoR. The cosine region parsing errors εcos are computed against both the Same and Reversed directions relative to the egocentric viewer's coordinate system. For example, native English speakers typically prefer a Reflected transformation, which maintains the lateral (left/right) axis but reverses the sagittal (front/back) axis relative to the viewer. We determine the preferred transformation based on the aggregated performance, with “–” for no significant preference.
Most VLMs Prefer Egocentric Relative Frame of Reference
| Model |
Back εcos (↓) |
Front εcos (↓) |
Left εcos (↓) |
Right εcos (↓) |
Aggregated |
Prefer |
| Ego. | Int. | Add. |
Ego. | Int. | Add. |
Ego. | Int. | Add. |
Ego. | Int. | Add. |
Ego. | Int. | Add. |
| InstructBLIP-7B |
41.0 | 38.6 | 38.6 |
40.9 | 46.9 | 46.9 |
45.6 | 32.5 | 51.9 |
39.6 | 51.2 | 31.8 |
41.8 | 42.3 | 42.3 |
- |
| InstructBLIP-13B |
32.9 | 34.4 | 34.4 |
52.5 | 48.5 | 48.5 |
47.8 | 56.2 | 27.8 |
40.6 | 27.6 | 56.6 |
43.5 | 41.7 | 41.8 |
- |
| mBLIP-BLOOMZ |
52.2 | 53.2 | 53.2 |
45.3 | 44.6 | 44.6 |
47.8 | 47.6 | 48.1 |
45.4 | 48.4 | 42.4 |
47.7 | 48.4 | 47.1 |
- |
| GLaMM |
28.0 | 49.1 | 49.1 |
30.0 | 40.0 | 40.0 |
14.0 | 56.8 | 41.5 |
13.7 | 53.0 | 46.6 |
21.4 | 49.8 | 44.4 |
Ego. |
| LLaVA-1.5-7B |
20.9 | 43.0 | 43.0 |
34.5 | 32.6 | 32.6 |
13.4 | 53.5 | 47.4 |
14.3 | 53.6 | 49.3 |
20.8 | 45.7 | 43.1 |
Ego. |
| LLaVA-1.5-13B |
31.9 | 38.8 | 38.8 |
24.8 | 57.1 | 57.1 |
11.7 | 51.1 | 51.1 |
27.5 | 57.4 | 48.7 |
24.0 | 51.1 | 48.9 |
Ego. |
| XComposer2 |
12.7 | 49.3 | 49.3 |
15.2 | 48.3 | 48.3 |
18.8 | 61.2 | 53.7 |
16.5 | 58.4 | 15.8 |
15.8 | 54.5 | 51.4 |
Ego. |
| MiniCPM-V |
34.2 | 40.7 | 40.7 |
35.5 | 53.4 | 53.4 |
18.0 | 53.9 | 53.9 |
19.0 | 58.1 | 26.7 |
26.7 | 51.5 | 51.3 |
Ego. |
| GPT-4o |
38.3 | 36.7 | 36.7 |
43.1 | 50.2 | 50.2 |
34.7 | 59.3 | 56.5 |
24.3 | 57.3 | 61.7 |
35.1 | 50.9 | 51.3 |
Ego. |
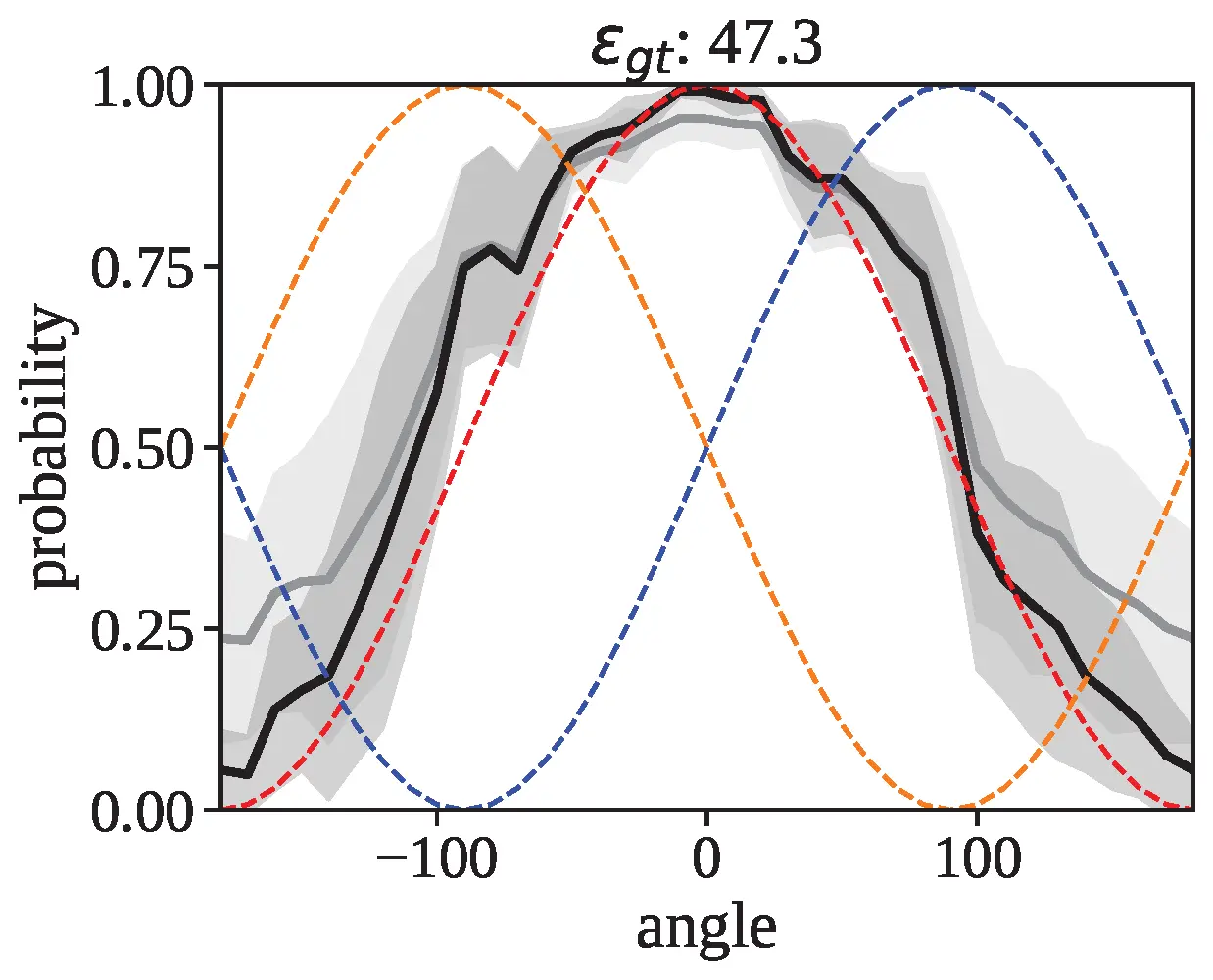
Preferred frame of reference in VLMs. Models' Cosine Region Parsing Errors εcos are computed against the Intrinsic FoR (relatum origin), Egocentric relative FoR (camera origin), and Addressee-centric relative FoR (addressee origin). English typically prefers an egocentric relative FoR. We determine the preferred FoR based on the aggregated performance, with “-” indicating no significant preference.
VLMs Fail to Adopt Alternative Frames of Reference Flexibly
| Model |
Egocentric |
Intrinsic |
Addressee |
Aggregated |
|
Acc% (↑) |
εcos×102(↓) |
Acc% (↑) |
εcos×102(↓) |
Acc% (↑) |
εcos×102(↓) |
Acc% (↑) |
εcos×102(↓) |
| InstructBLIP-7B |
47.2(+0.0) |
43.5(+1.7) |
47.2(+0.0) |
42.3(+0.0) |
47.2(+0.0) |
43.6(+1.3) |
47.2(+0.0) |
43.1(+1.0) |
| InstructBLIP-13B |
47.2(+0.0) |
43.8(+0.3) |
47.2(+0.0) |
43.2(+1.5) |
47.2(+0.0) |
42.9(+1.1) |
47.2(+0.0) |
43.3(+1.0) |
| mBLIP-BLOOMZ |
51.9(−0.9) |
55.4(+7.7) |
49.8(−3.0) |
54.2(+5.8) |
49.6(−3.2) |
55.8(+8.7) |
50.4(−2.4) |
55.1(+7.4) |
| GLaMM |
47.2(−10.6) |
23.3(−0.7) |
47.2(+0.8) |
44.2(−6.9) |
47.2(−2.8) |
42.8(−6.1) |
47.2(−4.2) |
36.8(−4.6) |
| LLaVA-1.5-7B |
55.2(−2.6) |
18.4(−3.0) |
48.3(+4.7) |
45.7(−4.1) |
48.2(−5.0) |
43.4(−1.0) |
50.6(−1.0) |
35.8(−2.7) |
| LLaVA-1.5-13B |
51.6(−15.0) |
23.9(+3.1) |
47.3(+0.8) |
45.0(−7.0) |
47.5(−3.8) |
38.9(−4.2) |
48.8(−6.0) |
35.9(−0.6) |
| XComposer2 |
85.6(−7.0) |
18.8(+3.0) |
51.0(+0.5) |
51.0(−3.3) |
53.2(−0.6) |
49.8(−1.6) |
63.3(−2.4) |
39.9(−0.6) |
| MiniCPM-V |
72.4(−4.8) |
24.6(−2.1) |
49.9(−2.6) |
47.8(−3.7) |
52.9(−0.5) |
45.1(−6.2) |
58.4(−2.6) |
39.2(−4.0) |
| GPT-4o |
78.3(+4.6) |
28.1(−7.0) |
53.4(−1.9) |
44.6(−6.3) |
49.1(−5.7) |
44.9(−6.4) |
60.3(−1.0) |
39.2(−6.6) |
The accuracy and cosine region parsing errors of VLMs with explicitly prompted to follow each frame of reference are provided (cam/rel/add). The values in parentheses indicate the performance change relative to the scenario with no perspective (nop) prompting.
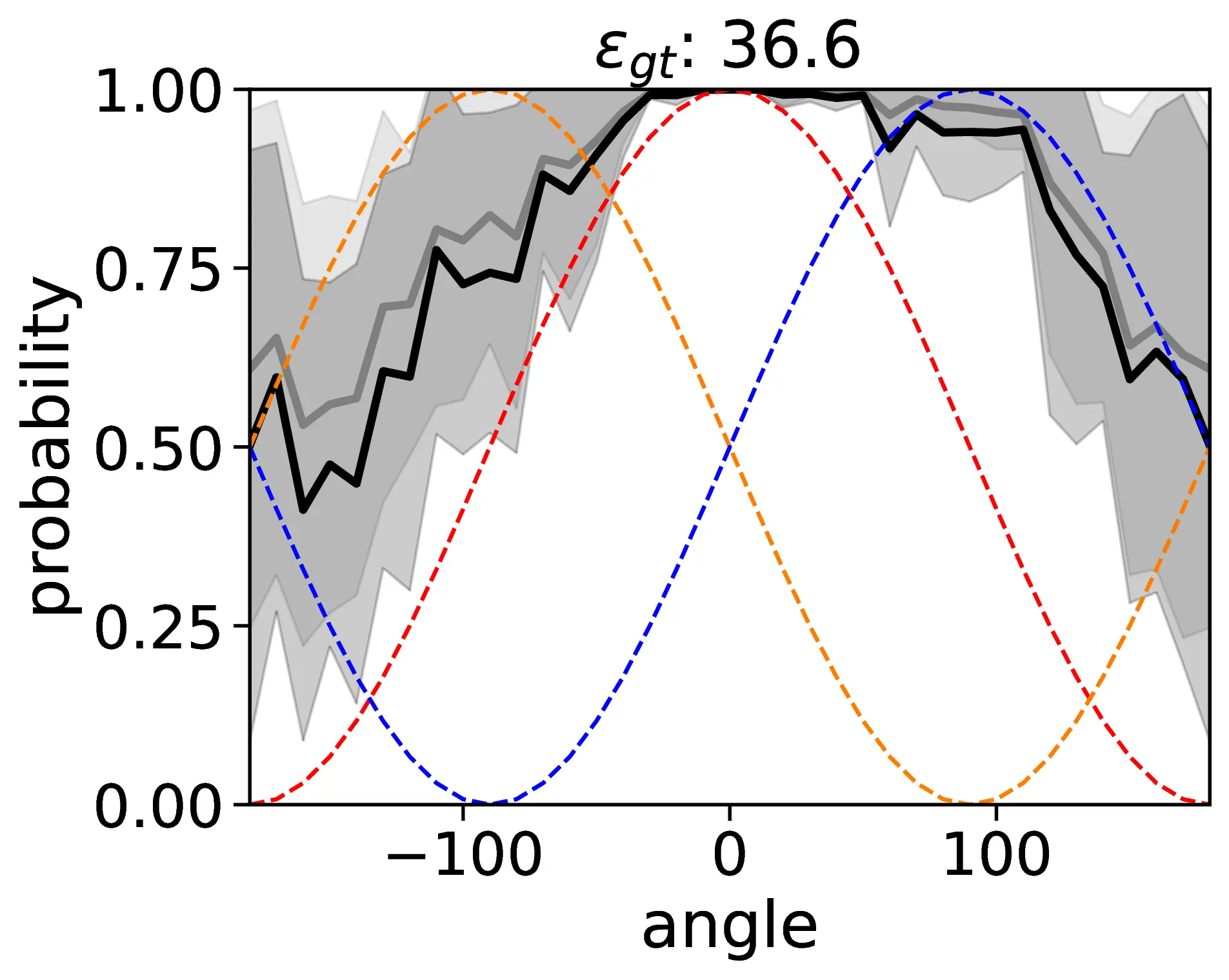
Spatial Representations in VLMs are Not Robust and Consistent
| Model |
Obj F1 (↑) |
Acc% (↑) |
εcos ×10² (↓) |
εhemi ×10² (↓) |
σ ×10² (↓) |
η ×10² (↓) |
csym ×10² (↓) |
copp ×10² (↓) |
| BALL |
CAR |
BALL |
CAR |
BALL |
CAR |
BALL |
CAR |
BALL |
CAR |
BALL |
CAR |
BALL |
CAR |
BALL |
CAR |
| InstructBLIP-7B |
66.7 |
66.7 |
47.2 |
47.2 |
43.9 |
43.5 |
57.8 |
56.4 |
26.7 |
30.5 |
48.4 |
43.4 |
17.2 |
16.9 |
16.6 |
22.6 |
| InstructBLIP-13B |
67.3 |
50.3 |
47.2 |
47.2 |
43.0 |
43.8 |
55.5 |
55.9 |
27.1 |
36.8 |
48.2 |
46.4 |
17.3 |
17.0 |
21.0 |
21.9 |
| mBLIP-BLOOMZ |
99.1 |
33.3 |
47.5 |
51.9 |
52.1 |
55.4 |
62.1 |
65.6 |
43.7 |
48.6 |
54.1 |
60.7 |
29.1 |
30.1 |
33.8 |
42.0 |
| GLaMM |
100.0 |
99.8 |
47.2 |
47.2 |
33.0 |
23.3 |
45.2 |
37.6 |
29.9 |
23.4 |
45.0 |
28.4 |
10.1 |
9.4 |
13.7 |
14.6 |
| LLAVA-1.5-7B |
100.0 |
88.6 |
63.2 |
55.2 |
20.7 |
18.4 |
33.7 |
32.5 |
25.2 |
20.0 |
23.5 |
21.8 |
5.8 |
5.4 |
8.3 |
10.7 |
| LLAVA-1.5-13B |
100.0 |
98.6 |
55.3 |
51.6 |
25.7 |
23.8 |
37.6 |
37.1 |
19.3 |
20.8 |
24.9 |
29.9 |
7.0 |
5.8 |
9.3 |
10.8 |
| XComposer2 |
100.0 |
95.3 |
92.4 |
85.6 |
20.0 |
18.8 |
21.1 |
26.3 |
19.2 |
15.3 |
13.7 |
22.9 |
9.0 |
6.5 |
10.5 |
12.0 |
| MiniCPM-V |
66.8 |
81.5 |
81.0 |
72.4 |
32.4 |
24.6 |
32.8 |
35.8 |
19.2 |
19.2 |
29.8 |
22.7 |
10.1 |
9.2 |
12.4 |
14.9 |
| GPT-4o |
100.0 |
94.5 |
89.2 |
78.3 |
27.4 |
28.1 |
27.5 |
35.0 |
20.9 |
24.0 |
43.1 |
38.8 |
14.1 |
13.3 |
14.2 |
16.7 |
| Random (30 trials) |
50.0 |
50.9 |
46.3 |
58.7 |
28.3 |
26.6 |
42.5 |
44.2 |
| Always “Yes” |
50.0 |
47.2 |
61.2 |
68.7 |
0.0 |
0.0 |
0.0 |
100.0 |
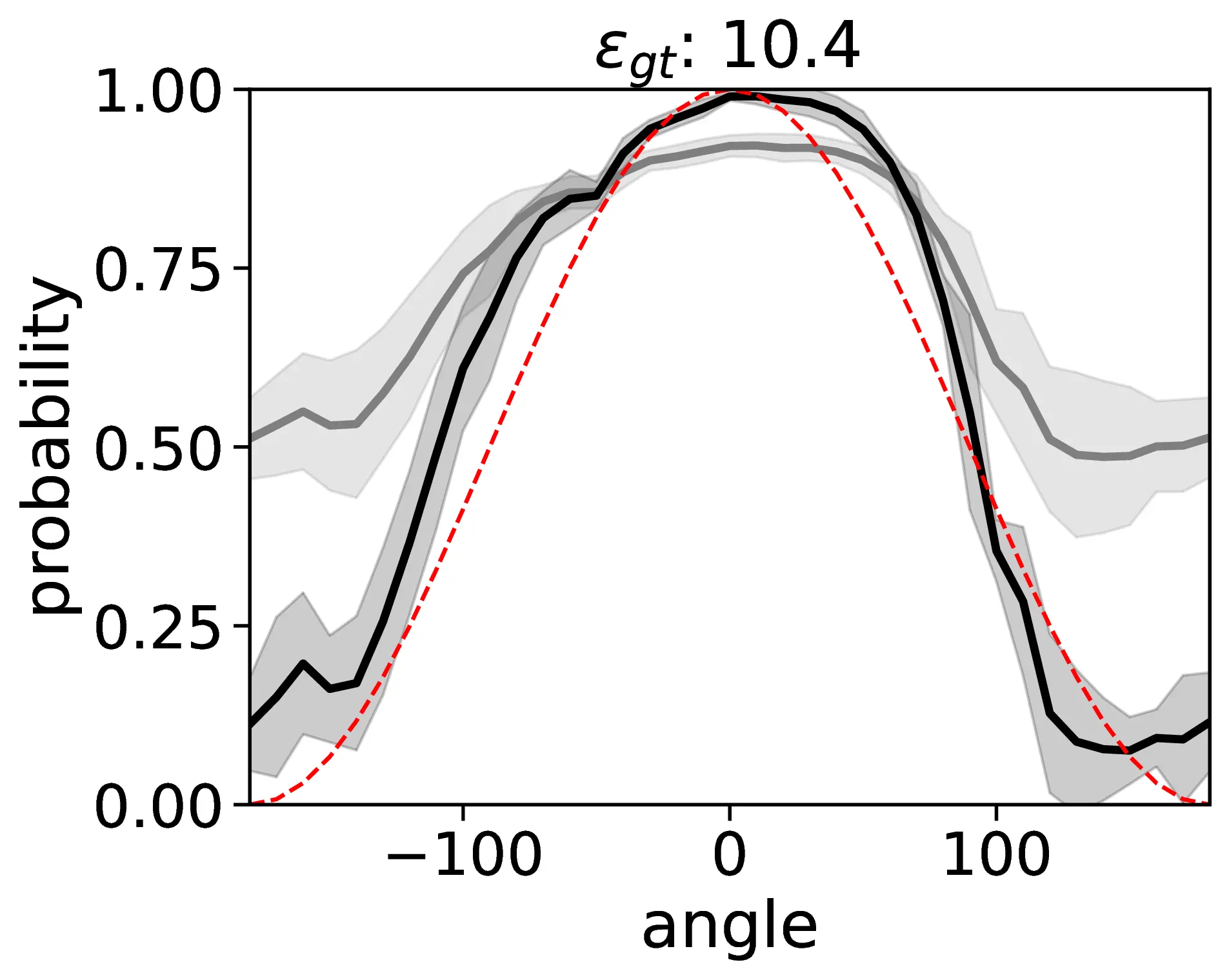
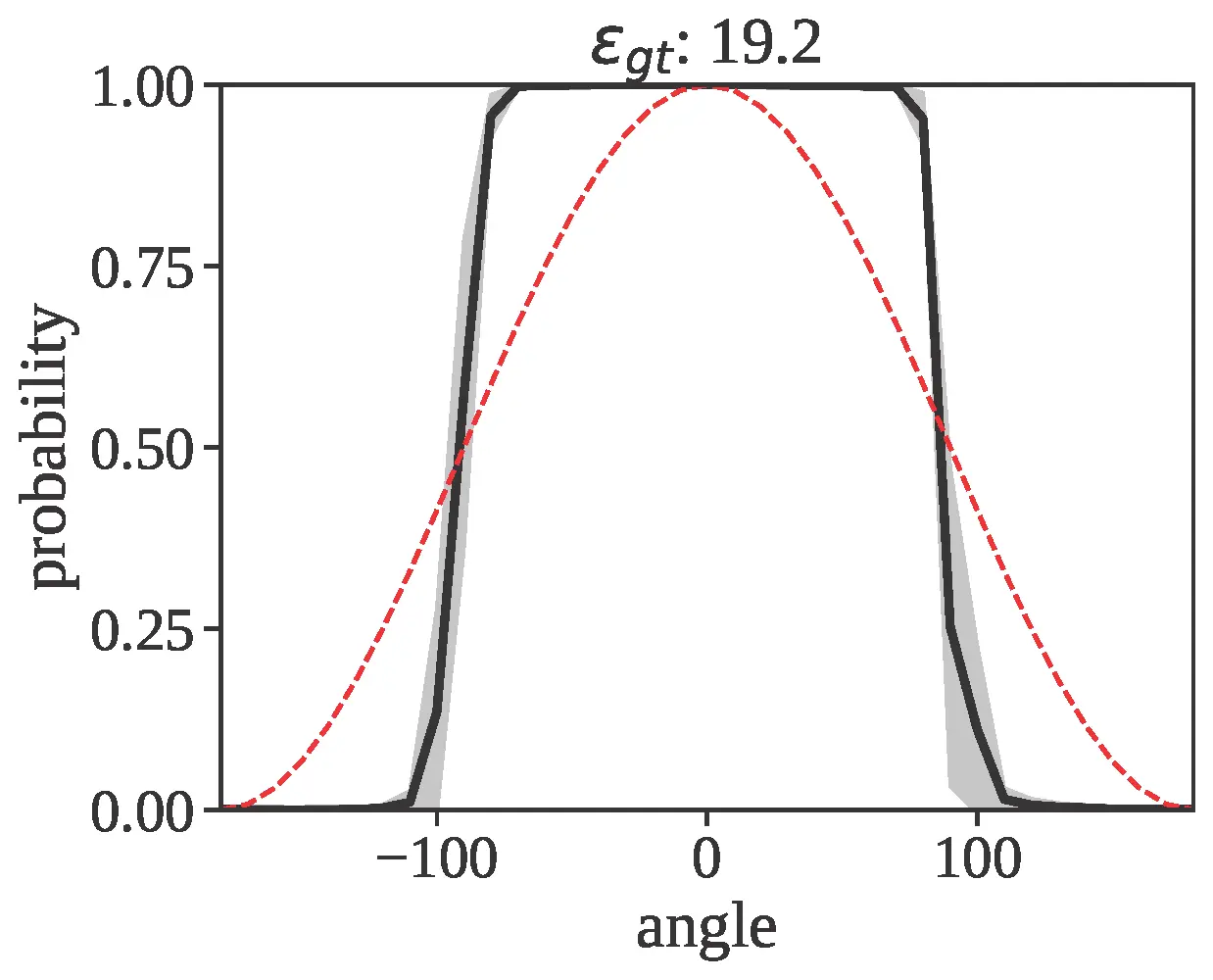
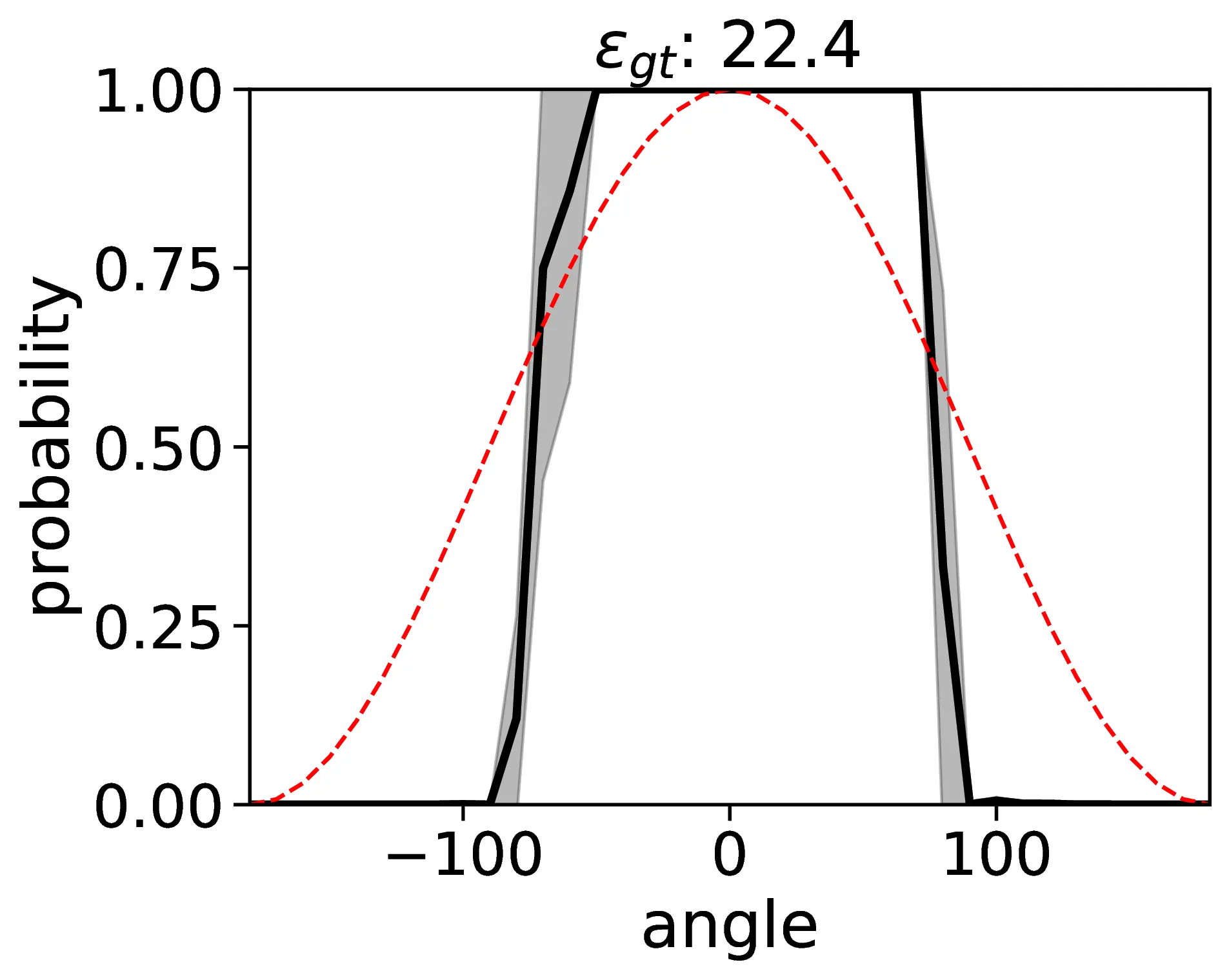
A comprehensive evaluation of VLMs in egocentric relative FoR with reflected transformation, using an explicit camera perspective (cam) prompt, is conducted. The metrics considered include object hallucination (F1-score), accuracy (Acc), region parsing error (ε), prediction noise (η), standard deviation (σ), and consistency (c).